
Celem wykładu jest omówienie zagadnień obsługi urządzeń wejścia-wyjścia (zwanych również urządzeniami zewnętrznymi lub peryferyjnymi) i realizacji związanych z tym mechanizmów w jądrze systemu operacyjnego. Problem obsługi urządzeń wejścia-wyjścia jest o tyle skomplikowany, że są to urządzenia bardzo zróżnicowane pod wieloma względami, stosunkowo wolne (w porównaniu z jednostką centralną) i stanowią najczęściej zmieniający się element konfiguracji systemu komputerowego. Z drugiej strony urządzenia wejścia-wyjścia stanowią „zmysły” komputera, dlatego większość z nich jest bardzo istotna dla użytkownika i jego interakcji z systemem. Można wręcz powiedzieć, że zwykły użytkownik postrzega komputer właśnie poprzez urządzenia wejścia-wyjścia. Efektywność i wygoda obsługi tych urządzeń, zwłaszcza w systemach interaktywnych, decyduje więc o ogólnym wrażeniu z jakości pracy z komputerem.

Urządzenia transmisji na odległość oprócz reakcji na sygnały sterujące ze strony jednostki centralnej reagują również na zdarzenia zewnętrzne, związane z przekazywaniem danych z innych jednostek. Należy tu też podkreślić, że każda komunikacja z urządzaniem zewnętrznym jest jakąś transmisją danych. Urządzenia transmisji danych na odległość służą do wymiany danych z innymi komputerami, więc chodzi tu o transmisję danych pomiędzy urządzeniami o podobnym charakterze, a nie transmisję pomiędzy jednostką centralną, a zintegrowanym z nią urządzeniem.
Urządzenia do komunikacji z człowiekiem w ogólności też reagują zarówno na zdarzenia wewnętrzne, jak i zewnętrzne. Zdarzenia zewnętrzne dotyczą przede wszystkim urządzeń wejściowych i związane są z działaniami człowieka (użytkownika). Są to więc zdarzenia, które zachodzą niezbyt często w porównaniu z szybkością pracy jednostki centralnej, a moment ich zajścia jest trudny do przewidzenia.

Zróżnicowanie urządzeń wejścia-wyjścia przejawia się między innymi w dużej liczbie klasyfikacji, wynikających z różnych kryteriów.
Ze względu na tryb transmisji wyodrębnia się urządzenie znakowe i blokowe. W przypadku urządzeń blokowych w wyniku operacji wejścia-wyjścia następuje przekazanie bloku o ustalonym rozmiarze np. 512 B. W przypadku urządzeń znakowych po przekazaniu bajta lub słowa konieczne jest zlecenie następnej operacji wejścia-wyjścia w celu odebrania kolejnej takiej jednostki. Urządzenia takie mają czasami wewnętrzny bufor, umożliwiający przekazywanie nieco większych porcji danych.
Podział na urządzenia sekwencyjne i bezpośrednie wiąże się z łatwością uzyskania dostępu do wybranego zakresu danych na urządzeniu. Większość urządzeń wejścia-wyjścia pracuje w sposób sekwencyjny, czyli przekazuje dane do jednostki centralnej w postaci pewnego strumienia bez możliwości ograniczenia do pewnego zakresu. Jednostka centralna może co najwyżej dokonać filtracji po odebraniu tych danych. Podobnie w przypadku przekazywania danych do urządzenia, nie ma możliwości wskazania kolejności przetwarzania czy zmiany kolejności ułożenia poszczególnych części. Jednym z niewielu urządzeń o dostępie bezpośrednim jest dysk. Przed zainicjalizowaniem właściwej operacji dostępu można odpowiednio ustawić pozycję głowicy oraz wskazać sektor do zapisu lub odczytu. Podobne podejście można by potencjalnie stosować w przypadku napędów taśmowych. Zasadnicza trudność wiąże się jednak z czasem pozycjonowania, wymagającym długotrwałego przewijania taśmy. Dlatego napędy taśmowe są urządzeniami o dostępie sekwencyjnym.

Pewne urządzenia mogą współbieżnie obsługiwać zlecenia wielu procesów. Dla urządzenie nie ma znaczenia jaki proces czy użytkownika obsługuje. Pojęcie procesu na poziomie architektury nawet nie istnieje. Ma to natomiast znaczenia dla użytkownika. Dla użytkownika nie ma znaczenia, czy dysk zapisując jego dane, wplecie pomiędzy operacje zapisu poszczególnych sektorów, operacje zapisu lub odczytu innych sektorów, wynikające z osobnego zlecenia. Co najwyżej nastąpi opóźnienie realizacji całego zlecenia zapisu, jest to jednak raczej nieodczuwalne. Trudno jednak taki przeplot zaakceptować na wydruku — jest mało prawdopodobne, żeby wydruk był czytelny.

Kierunek przekazywania danych dotyczy danych przetwarzanych, a nie sygnałów sterujących, czy informacji o stanie urządzenia. Drukarka jest typowym urządzeniem wyjściowym, ale można odczytać jej stan (np. informację o braku papieru, tonera itp.). Nie służy ona natomiast do wprowadzania danych.

Interakcja jednostki centralnej z urządzeniem wejścia-wyjścia sprowadza się do zapisu lub odczytu odpowiednich rejestrów sterownika. Sterownik może być umieszczony na płycie głównej (np. karta graficzna) lub na płytce urządzenia (np. sterownik dysku, sterownik drukarki). Sterownik na płycie głównej lub ta jego część, która przystosowana jest do współpracy z magistralą systemu komputerowego, nazywany jest adapterem. W przypadku niektórych urządzeń komunikacja pomiędzy sterownikiem, a adapterem na płycie odbywa się za pośrednictwem specjalnej magistrali (np. magistrali SCSI). Procesor ma wówczas bezpośredni dostępu do rejestrów adaptera, który komunikuje się ze sterownikiem. W przypadku, kiedy sterownik nie jest zintegrowany z adapterem, komunikacja pomiędzy urządzeniem zewnętrznym a jednostką centralną może odbywać się przez odpowiedni port standardowy, np. port szeregowy (RS-232, USB) lub port równoległy. W tym przypadku procesor również nie ma bezpośredniego dostępu do rejestrów sterownika i wszystkie operacje zapisu oraz odczytu musi wykonać za pośrednictwem sterownika portu i jego rejestrów.
Zadaniem systemu operacyjnego jest między innymi ułatwienie dostępu do urządzeń, przez ujednolicenie i uproszczenie interfejsu, czyli ukrycie szczegółów realizacji urządzenia. Odpowiada za to przede wszystkim moduł sterujący (moduł obsługi urządzenia, ang. device driver).

Sposób implementacji tych funkcji zależy od specyfiki urządzenia. Implementacja taka dostarczana jest przez moduł sterujący. Moduł sterujący dostarcza też procedur, które nie są dostępne w interfejsie dla aplikacji, ale wywoływane są np. w ramach obsługi przerwania, zgłaszanego przez urządzenie.
Moduły sterujące dostarczane są dla typowych systemów operacyjnych (np. Windows XP, Solaris, Linux) przez twórców systemów operacyjnych lub wytwórców urządzeń wejścia-wyjścia. Moduł sterujący jest taką częścią oprogramowania systemowego, które może wymagać modyfikacji i uzupełnień, zależnie od urządzeń dołączanych do komputera. Jądro systemu operacyjnego musi więc dostarczyć odpowiednie mechanizmy, umożliwiające dołączanie nowych modułów. W skrajnym przypadku sposobem dołączania nowego modułu jest rekompilacja jądra. Metoda taka stosowana była w klasycznym systemie UNIX, dlatego elementem standardowego oprogramowania tych systemów był między innymi kompilator języka C.
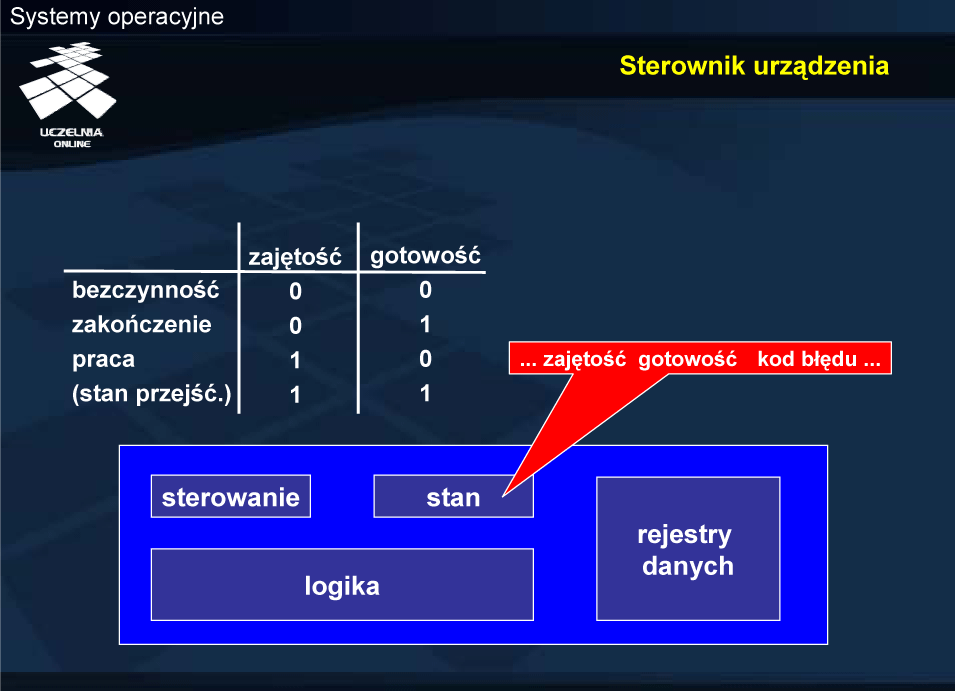
Liczba i wielkość rejestrów sterownika zależą od konkretnych rozwiązań. W typowym sterowniku można jednak wyróżnić następujące rejestry:

Niektóre urządzenia udostępniają część swoich rejestrów w przestrzeni adresowej wejścia-wyjścia, a część w przestrzeni adresowej pamięci (np. karta graficzna).

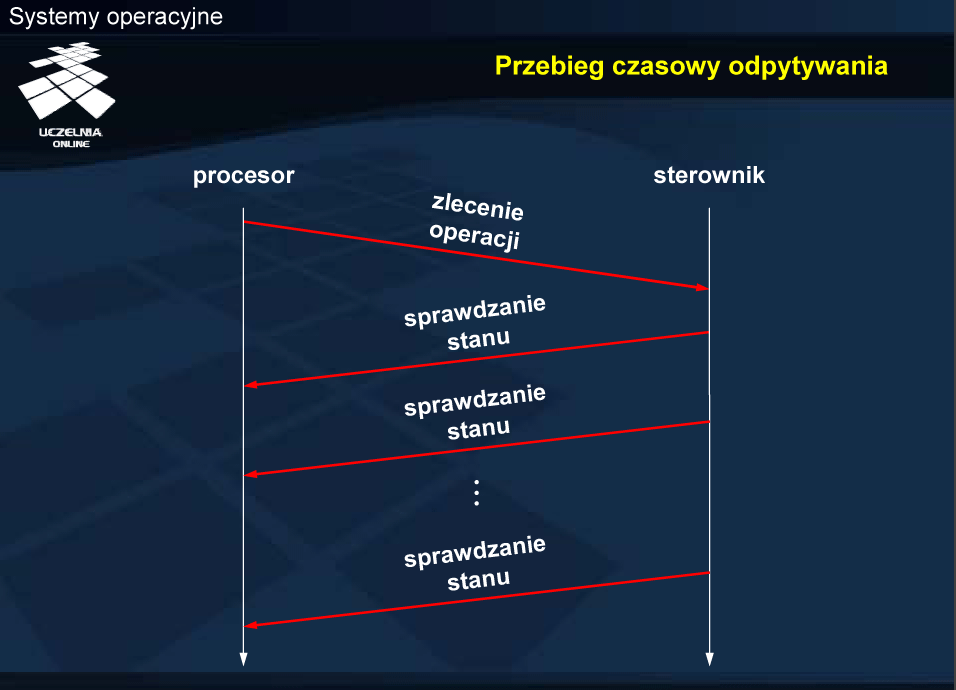
W przypadku odpytywania procesor jest odpowiedzialny zarówno za monitorowanie stanu sterownika (np. w celu stwierdzenia zakończenia operacji) jak i transfer danych. Procesor jest więc zobligowany do ciągłego lub okresowego sprawdzania rejestru stanu sterownika, co wymaga odpowiedniej konstrukcji modułu sterującego. Podejście tego typu określa się jako aktywne czekanie . Odpytywanie może być stosowane w przypadku urządzeń synchronicznych, wykonujących krótkotrwałe operacje wejścia-wyjścia.
W przypadku sterowania przerwaniami procesor jest odpowiedzialny za transfer danych, ale nie musi monitorować w sposób ciągły stanu sterownika. Inicjalizuje on pracę sterownika a o jej zakończeniu lub zaistnieniu określonego stanu informowany jest przez przerwanie, które zgłasza sterownik. W oprogramowaniu systemowym należy zatem uwzględnić procedurę obsługi przerwania a jej adres umieścić na właściwej pozycji wektora przerwań.
W przypadku zastosowania układu DMA, po zainicjalizowaniu pracy urządzenia przez procesor, przekazywanie danych pomiędzy sterownikiem a pamięcią realizowane jest przez specjalizowany układ (DMA), który wykonuje swoje zadanie bez angażowania procesora. Zależnie od architektury, zadanie takie może również wykonywać procesor wejścia-wyjścia, który może nawet dysponować własną, prywatną pamięcią.
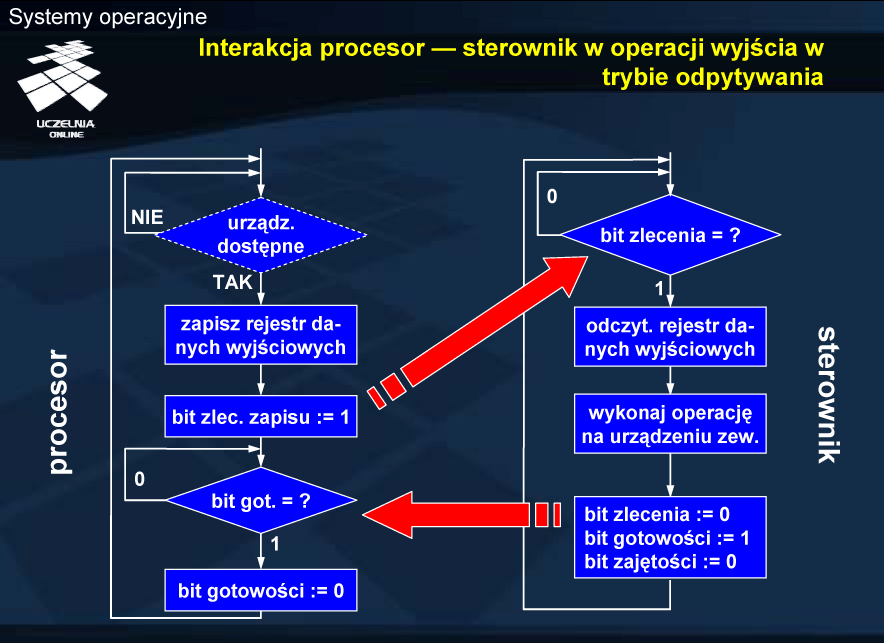
Dla uproszenia dalszej prezentacji przyjęto, że ustawienie bitu gotowości po zakończeniu operacji oznacza pomyślne zakończenie. Brak ustawienia bitu gotowości oznacza błąd, co z kolei jest sygnalizowane przez odpowiednie bity kodu błędu w rejestrze stanu. W przypadku operacji wyjścia bit gotowości oznacza zatem, że udało się przekazać zawartość rejestru danych do urządzenia i ją przetworzyć.
Sterownik urządzenia czeka na zlecenie od procesora, sprawdzając bit gotowości zlecenia zapisu. Należy w tym miejscu podkreślić różnicę pomiędzy bitem gotowości urządzenia w rejestrze stanu oraz bitem gotowości zlecenia (nazywanym krótko bitem zlecenia) w rejestrze sterowania. Procesor, realizując program modułu sterującego, sprawdza, czy urządzenie jest dostępne (czy bity gotowości i zajętości są skasowane). Dla uproszczenia przyjęto, że robi to również w trybie odpytywania. Biorąc pod uwagę fakt, że procesor oczekuje na zakończenie operacji wejścia-wyjścia, odczytując rejestr stanu, nie wydaje się możliwe, aby urządzenie było zajęte, a procesor realizował kolejne zlecenie. Sytuacja taka mogłaby ewentualnie mięć miejsce w systemach wieloprocesorowych lub w przypadku odpytywania okresowego.
Operacja wyjścia polega na zapisaniu rejestru danych wyjściowych, a następnie ustawieniu bitu gotowości polecenia zapisu. Po wydaniu zlecenia procesor przechodzi w tryb odpytywania rejestru stanu w celu sprawdzenie bitu gotowości, a sterownik realizuje zlecenie. Po zrealizowaniu zlecenia sterownik ustawia bit gotowości (na co czeka procesor) oraz kasuje bit zajętości i przechodzi do oczekiwania na kolejne zlecenie.
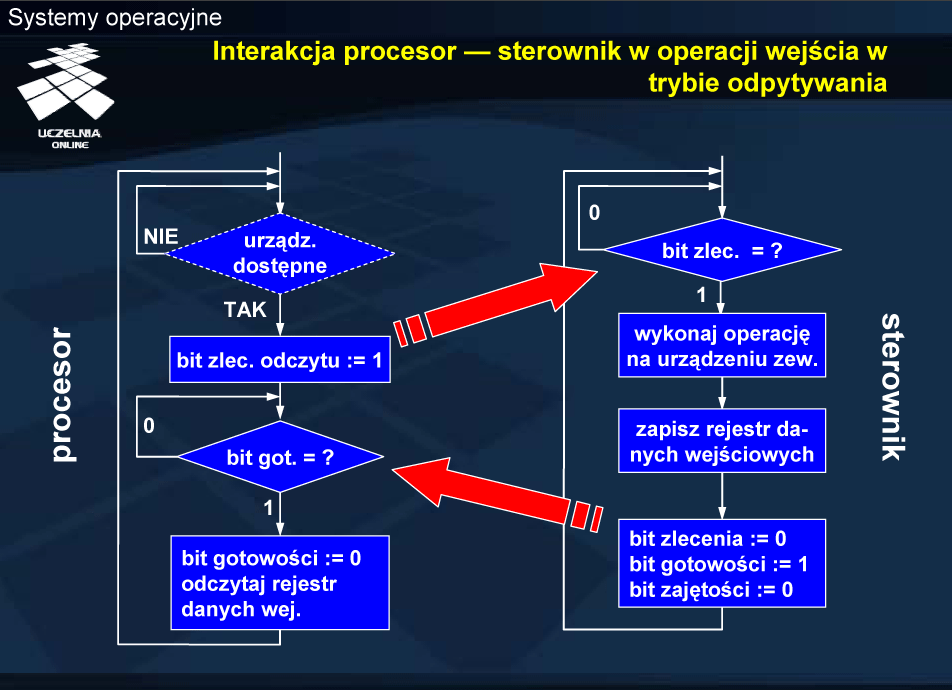
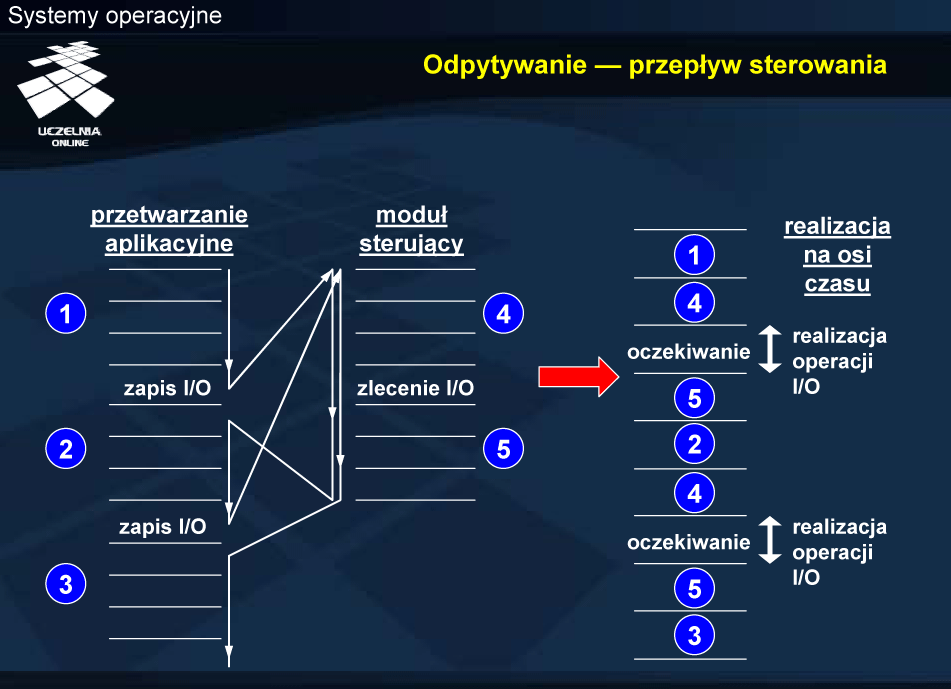
W międzyczasie centralny procesor może realizować przetwarzanie użytkowe. Proces, który zlecił wykonanie operacji zostaje najczęściej zablokowany w oczekiwaniu na zakończenie, ale dostępny może być inny proces gotowy. W ten sposób można równoważyć obciążenie systemu, co było głównym celem wprowadzenie wielozadaniowości i związanej z nią koncepcji procesu. Nawet gdyby nie było żadnego procesu gotowego, to procesor może wykonać pewne zadania systemowe, np. zapisać profilaktycznie na urządzeniu wymiany zawartość brudnych ramek pamięci fizycznej. W ostateczności będzie wykonywana pętla bezczynności, zwana również wątkiem bezczynności. Pętla bezczynności jest oczekiwaniem na przerwanie, a więc specyficznym odpytywaniem linii wejściowej przerwań w procesorze.
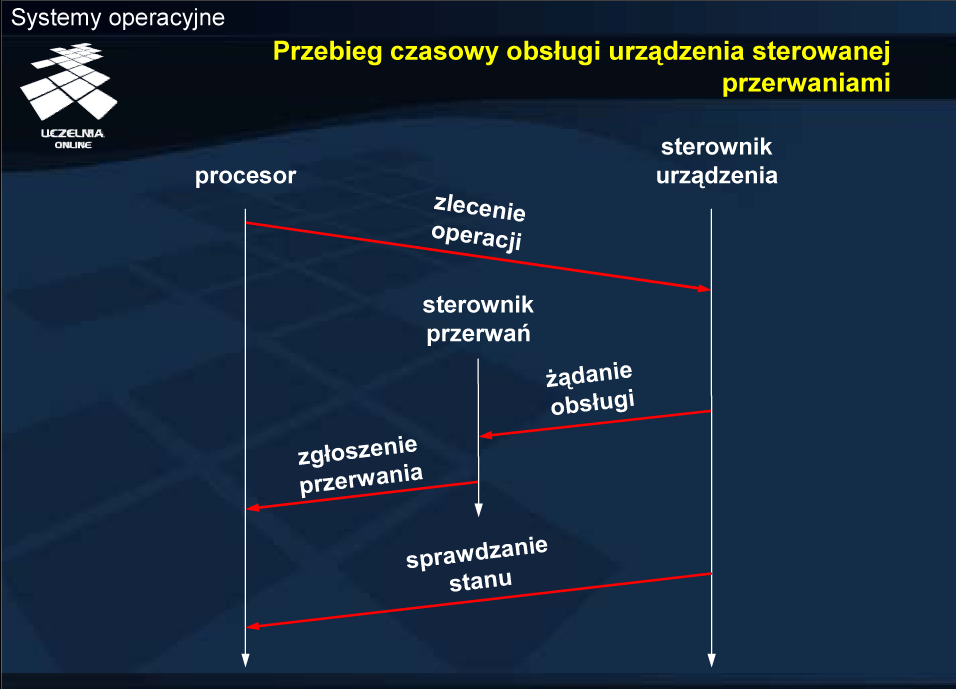
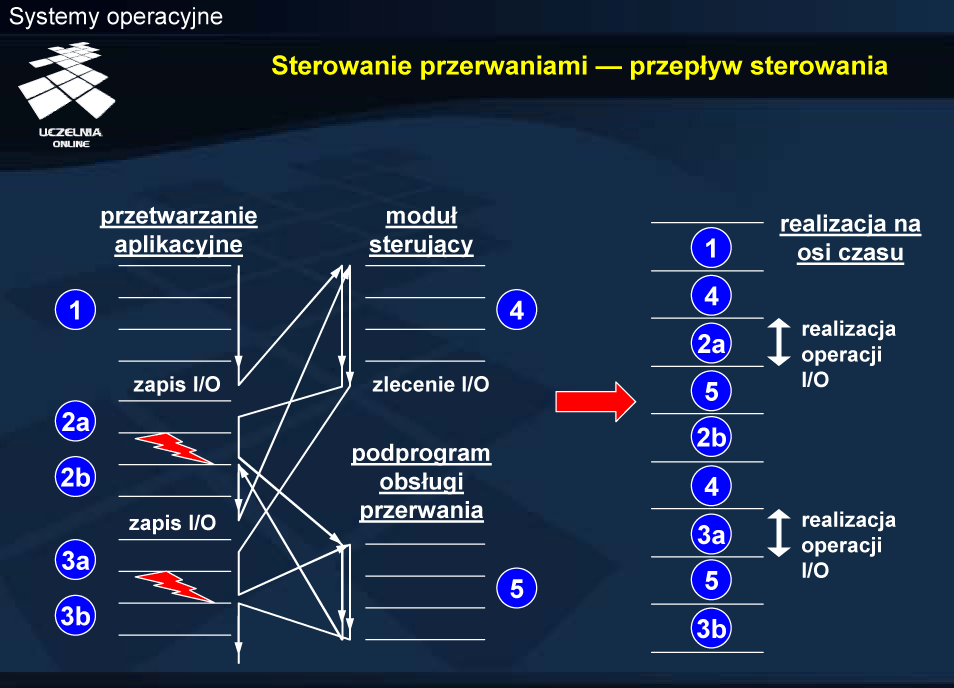
Po zakończeniu pracy urządzenia wejścia-wyjścia sterownik, oprócz ustawienia odpowiednich bitów stanu, zgłasza przerwanie. Pośrednikiem w przekazywaniu przerwania do procesora jest sterownik przerwań. Ma on kilka linii wejściowych i jedną wyjściową, za pośrednictwem której przekazuje sygnał na odpowiednie wejście procesora. Obsługa urządzenia po zakończeniu pracy realizowana w reakcji na przerwanie. Zanim nastąpi obsługa konieczne jest zidentyfikowanie źródła przerwania. Nie zawsze też całość obsługi urządzenia realizowana jest w procedurze obsługi przerwania. Niektóre czynności mogą zostać odroczone i wykonane poza procedurą obsługi przerwania.
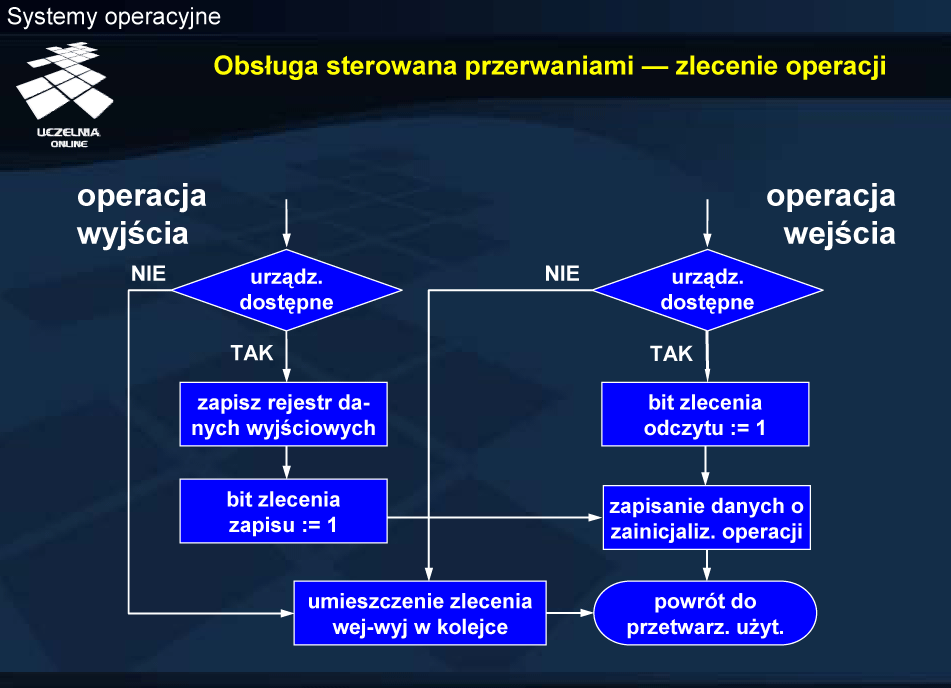
Po zleceniu operacji następuje zapisanie informacji o tej operacji w tablicy urządzeń i powrót do przetwarzania aplikacyjnego. Jest to jedna część realizacji operacji wejścia-wyjścia. Implementacja tej części określana jest w module sterującym jako górna połowa. (Nieco inaczej termin górna i dolna połowa rozumiany jest w systemie Linux).
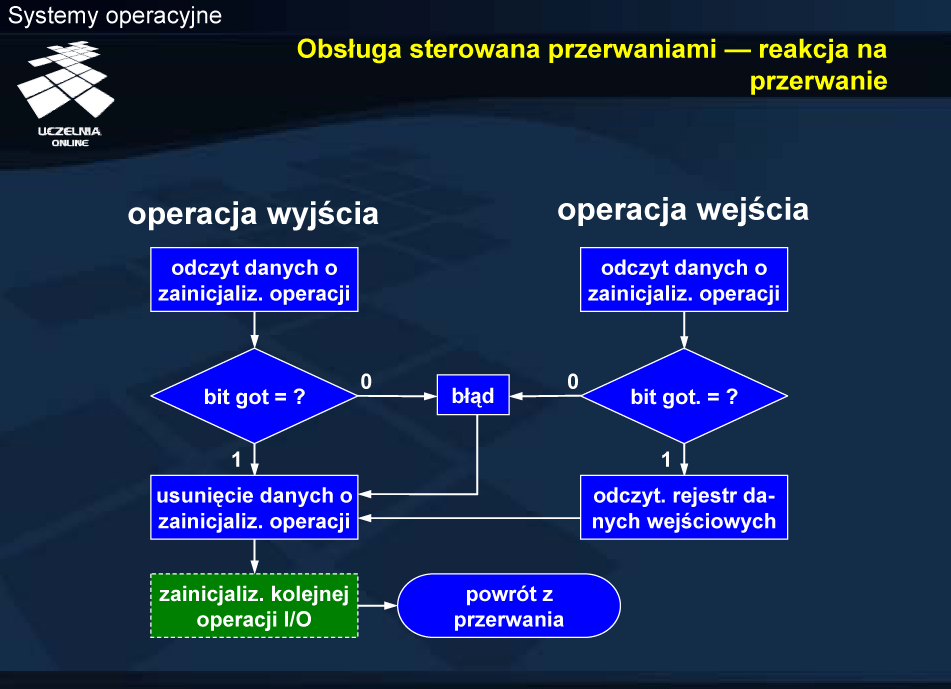
Podprogram obsługi przerwania wykonuje pewne zadania ogólne, niezależne od źródła przerwania oraz identyfikuje źródło przerwania. Właściwą obsługę urządzenia realizuje podprogram obsługi urządzenia, określany jako dolna połowa modułu sterującego. Wykonanie dolnej połowy polega na odczytaniu odpowiednich informacji z tablicy urządzeń, a następnie sprawdzeniu stanu sterownika (stanu zakończenia operacji) i przekazaniu danych i/lub informacji statusowych do procesu zlecającego wykonanie operacji.
Jeśli w kolejce do urządzenia znajdują się kolejne żądania, wybierane jest jedno z nich i zlecana jest następna operacja wejścia-wyjścia.
Procedura obsługi przerwania musi być wykonana dość szybko ze względu na blokowanie obsługi innych przerwań. Pewne czasochłonne zadania, związane z przetwarzaniem danych w ramach operacji wejścia-wyjścia, mogą być wykonane później, poza obsługą przerwania. Określa się je jako czynności odroczone, a w systemie Linux nazywa dolną połową, podczas gdy górna połowa oznacza część kodu, wykonywaną bezpośrednio w reakcji na przerwanie. Przykładem czynności odroczonych jest interpretacja zawartości ramki, odebranej przez kartę sieciową. Zawartość bufora karty musi być skopiowana możliwie szybko, a dalsze przetwarzanie, np. sprawdzenie poprawności, interpretacja adresów itp., mogą być wykonane nieco później.

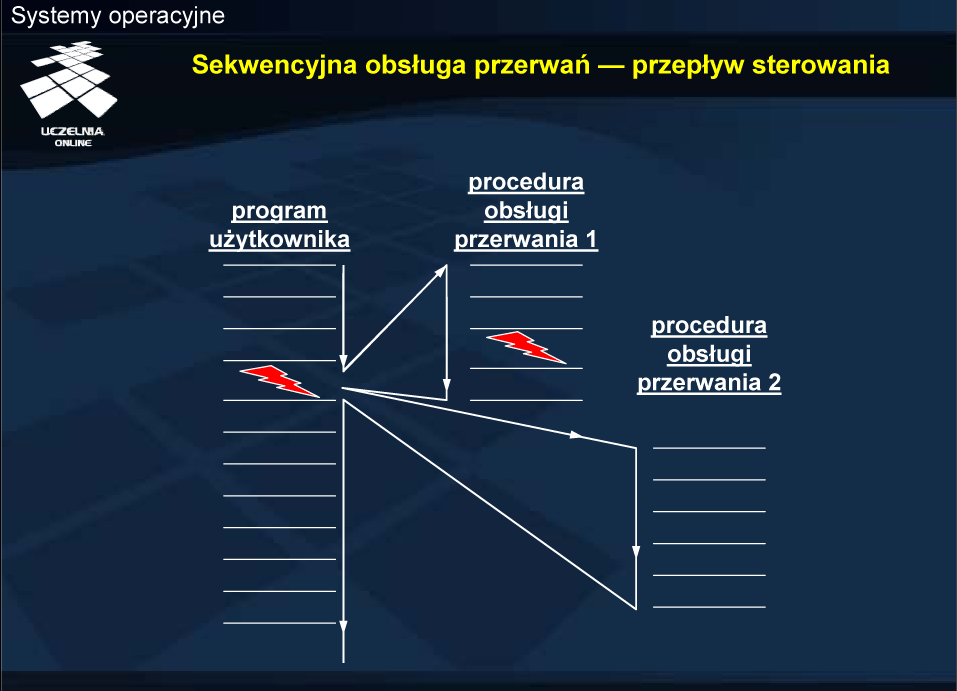
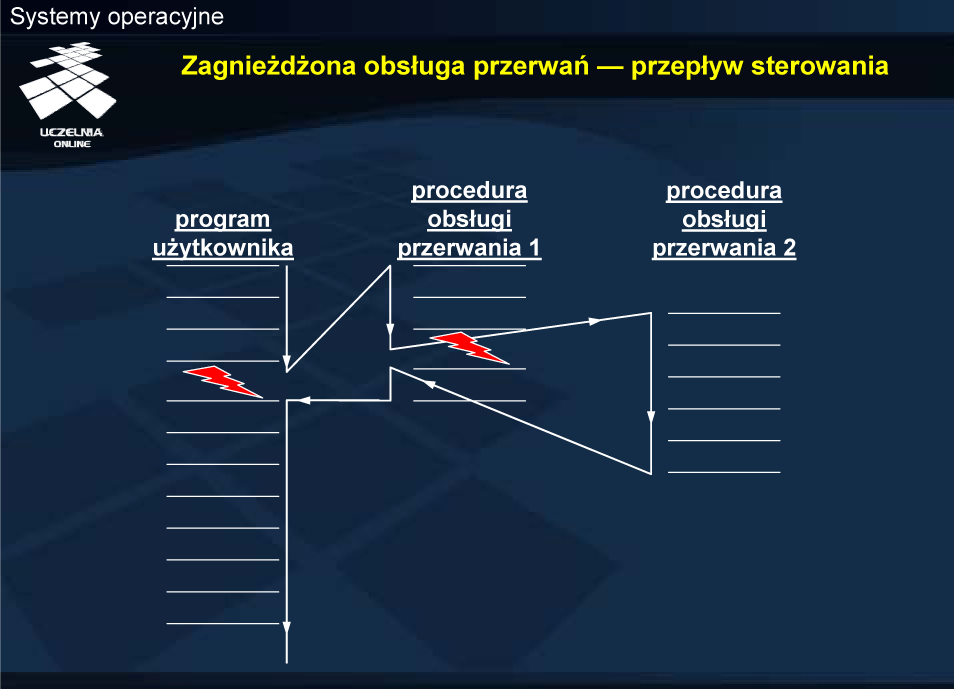
Ogólnie można wyróżnić kilka podejść do obsługi przerwań wielokrotnych:
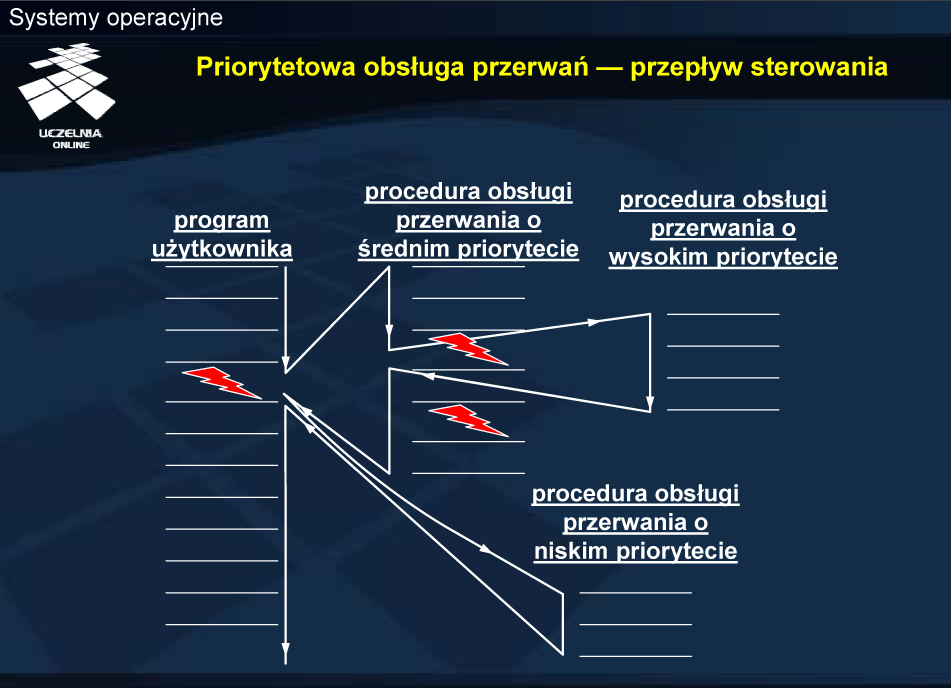
Podejście priorytetowe jest oczywiście powszechnie stosowane w obsłudze przerwań.


Odpytywanie programowe wymaga odczytania i zinterpretowania stanu każdego urządzenia. Można się oczywiście ograniczyć do tych urządzeń, dla których w tablicy urządzeń jest odnotowany fakt realizacji operacji. Wymaga to jednak przeglądania tablicy urządzeń, ogólnie jest więc czasochłonne.
Odczyt wektora wymaga umieszczenia odpowiednich informacji (numeru urządzenia, adresu urządzenia lub numeru przerwania) na magistrali. Informacja może zostać wystawiona po potwierdzeniu otrzymania przerwania przez procesor (odpytywanie sprzętowe). Sygnał potwierdzający otrzymanie przerwania propagowany jest łańcuchowo przez urządzenia aż do napotkania tego, które zgłosiło przerwanie. Innym sposobem jest uzyskanie wyłączności dostępu do magistrali i wystawienie odpowiedniego wektora przed zgłoszeniem przerwania (arbitraż na magistrali).
Rozwiązaniem hybrydowym jest użycia sterownika przerwań. Ma on wiele linii wejściowych i jedną wyjściową, podłączoną do odpowiedniego wejścia procesora. Po stwierdzeniu przerwania wystarczy odpytać sterownik przerwań, na której linii nastąpiło zgłoszenie. Sterownik przerwań ma jednak taką samą wadę, jak procesor, jeśli chodzi o liczbę wejściowych linii przerwań. Dlatego podejście to łączy się z odpytywaniem programowym. Wiele urządzeń może zgłaszać przerwanie o tym samym numerze. Obsługa przerwania rozpoczyna się od zidentyfikowania numeru przerwania, a następnie odpytywane są wszystkie urządzenie, które zgłaszają przerwanie o tym numerze. W praktyce wygląda to tak, że z każdym numerem przerwanie związany jest łańcuch modułów sterujących. W ramach obsługi przerwania uruchamiana jest odpowiednia procedura kolejnego modułu, a jaj zadaniem jest stwierdzenie, czy urządzenie przez nią obsługiwane uzyskało stan gotowości.

Na każdym wyższym poziomie jądro oczywiście nie reaguje również na zdarzenia przypisane do niższego poziomu.
W konkretnych implementacja tych poziomów może być więcej. W systemie Windows 2000/XP występują 32 tzw. poziomy zgłoszeń przerwań . W systemach Linux i Solaris do obsługi przerwań wykorzystywane są wątki jądra i ich priorytet decyduje o realizacji określonej procedury.


W przypadku przerwań narzut wynika z:

Różnica pomiędzy odpytywaniem a sterowaniem przerwaniami jest tylko w narzucie czasowym, który jest mniejszy w przypadku odpytywania.
Rozważając system wielozadaniowy, jeśli proces uzyska procesor, odpytywanie jest dla niego korzystniejsze, gdyż narzut czasowy jest mniejszy, a oczekiwanie na gotowość urządzenia jest z jego punktu widzenia czasem marnowanym (nie ma wówczas postępu w realizacji


W wariancie optymistycznym zawsze po wejściu w stan oczekiwania procesu zlecającego operację wejścia-wyjścia jest jakiś inny proces gotowy. Oznacza to, że w czasie, gdy proces oczekuje na dostępność urządzenia lub przydział procesora, procesor wykonuje inne zadanie. Jedynie sama obsługa przerwania angażuje procesor i w tym czasie nie może on wykonywać przetwarzania aplikacyjnego.
W wariancie pesymistycznym wszystkie procesy w tym samym czasie zlecają wykonanie operacji wejścia-wyjścia na tym samym urządzeniu, a urządzenie przydzielane jest temu procesowi, którego zlecenie jest najbardziej czasochłonne.

Czas skumulowanej obsługi przerwań, nawet w wariancie pesymistycznym, musiałby być znaczący, żeby kwestionować ogólną zasadność obsługi urządzeń wejścia-wyjścia sterowanej przerwaniami. Takie podejście mogłoby jedynie mieć sens w przypadku bardzo szybkich urządzeń, które potrafią zrealizować operację wejścia-wyjścia w czasie kilkunastu lub kilkudziesięciu cykli rozkazowych.
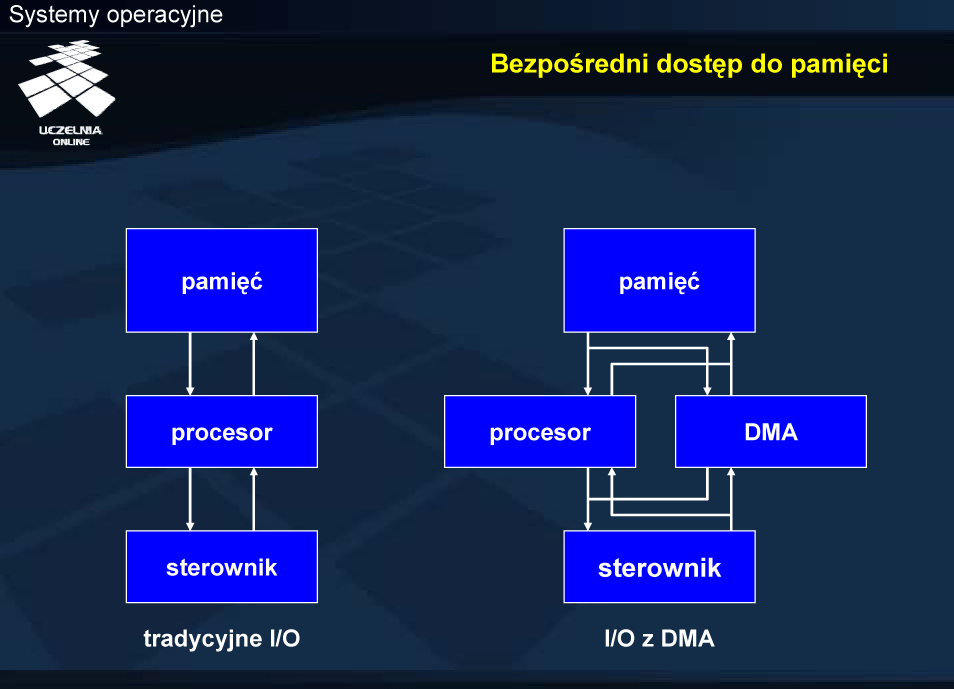
Układ DMA wykorzystywany jest w celu realizacji transferu większych bloków danych, np. w przypadku dysku lub karty sieciowej.
Procesor zleca układowi DMA transmisję danych, przekazując następujące parametry:
W celu realizacji zlecenia układ DMA przejmuje kontrolę nad magistralą, gdy nie jest ona potrzebna procesorowi lub „wykrada” cykl magistrali procesorowi i realizuje przesłanie słowa. Fakt zakończenia transmisji bloku danych układ DMA sygnalizuje procesorowi, zgłaszając przerwanie.
Pomimo ograniczeń w jednoczesnej pracy procesora i układu DMA, wynikającej z konieczności zapewnienia wyłącznego dostępu do magistrali, realizacja transferu bloku z udziałem DMA daje poprawę efektywności. Przekazanie bloku słowo po słowie przez procesor, przeplatane z realizacją przetwarzania aplikacyjnego, wymaga przerwania, powrotu z przerwania, zmiany zawartości niektórych rejestrów (przechowania i odtworzenia odpowiednich wartości). Poza tym procesor korzysta z pamięci podręcznej i nie zawsze wymagany jest dostęp do magistrali systemowej w cyklu rozkazowym.
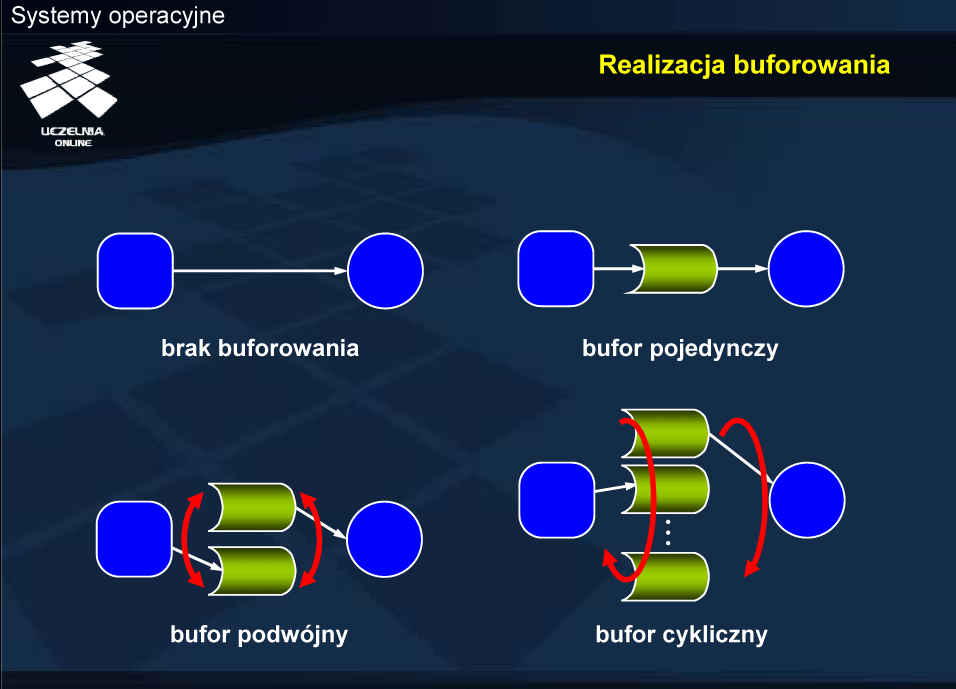
Buforowanie

Różnice mogą dotyczyć szybkości pracy urządzeń. Typowy przypadek dotyczy szybkiego producenta, przekazującego dane, z których przetwarzaniem nie nadąża odbiorca — konsument. Czasami, w celu równoważenia obciążenia urządzenia szybsze otrzymują więcej pracy do wykonania, w związku z czym nie mogę natychmiast reagować na żądania urządzeń powolnych. Wówczas również przydaje się buforowanie.
Inny przypadek dotyczy efektywności transmisji danych pomiędzy urządzeniami blokowymi. Bloki przekazywane przez jedno urządzenie mogą mieć innych rozmiar, niż bloki akceptowane przez inne urządzenie. W celu uniknięcia zbędnych operacji wejścia-wyjścia dane gromadzi się w buforze w celu „uformowania” jednostki o właściwym rozmiarze.
Nieco odmiennym przypadkiem jest semantyka kopii. Przypadek ten wiąże się z synchronizacją współbieżnego dostępu, a dokładniej koniecznością uniknięcia długotrwałego blokowania dostępu do danych. W tym celu robi się kopie danych w pamięci, które następnie można przekazać do urządzenia, podczas gdy proces może operować na danych oryginalnych.
W obsłudze drukarki stosowany jest dodatkowo tzw. spooler, co zostanie omówione z dalszej części.

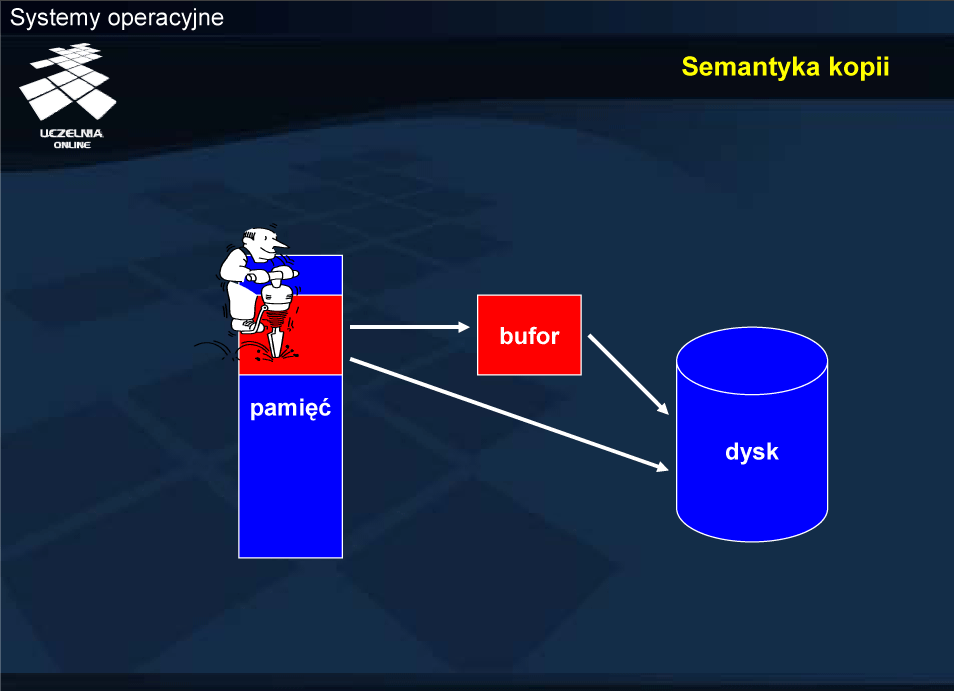
Można by oczywiście zablokować dostęp do obszaru pamięci z bieżącą zawartością pliku, ale zmusza to użytkownika do przerwania pracy na czas zapisu na dysku. Można zatem wykonać znacznie szybszą operację skopiowania odpowiedniego obszaru pamięci do bufora w jądrze, gdzie będzie gwarancja niezmienności danych.

W przypadku zlecenia odczytu danych z urządzenia są one przekazywane procesowi z bufora w pamięci podręcznej, z pominięciem operacji wejścia. Wymaga to utrzymania aktualnych danych w buforze pamięci podręcznej, a więc w wyniku operacji zapisu na urządzeniu musi nastąpić stosowana zmiana zawartości tego bufora. Operacja wyjścia może się ograniczyć do modyfikacji zawartości bufora. Właściwa operacja wyjścia na urządzeniu może nastąpić później i uwzględnić kilka zleceń zapisu ze strony procesów aplikacyjnych.
Tego typu technika stosowana jest powszechnie w obsłudze systemu plików, co będzie omawiane w następnych modułach. Jest ona również stosowana w obsłudze pamięci wirtualnej, ale w tym przypadku odnosi się do zawartość pamięci , urządzenie wymiany jest zatem wtórnym miejscem gromadzenia danych.

Operacja sekwencyjna jest tutaj rozumiana jako operacja na urządzeniu o dostępie wyłącznym. Następna operacja może się rozpocząć dopiero po zakończeniu poprzedniej. Konieczne jest więc zagwarantowanie ciągłości strumienia danych, przekazywanych do urządzenia w ramach operacji wyjścia. Strumień taki nie może się przeplatać z innym strumieniem. Typowym przykładem urządzenia, obsługiwanego z wykorzystaniem techniki spoolingu, jest drukarka. Przeplatanie strumieni w przypadku takiego urządzenia oznacza wydruk, który może być zupełnie nieczytelny (pomieszanie linii, słów, znaków lub zupełna abstrakcja w przypadku grafiki).
Spooling polega więc na buforowaniu strumienia danych, przekazywanych do urządzenia dostępnego w trybie wyłącznym i rozpoczęciu operacji dopiero po zapamiętaniu całego strumienia. Ze względu na objętość strumienia buforowanie takie odbywa się najczęściej na dysku (tzw. spooler). Przekazywanie danych ze spoolera do urządzenia realizuje jeden proces lub wątek, co zapewnia sekwencyjność tej operacji.
Alternatywą dla spoolingu byłoby blokowanie urządzenia, tzn. jawny przydział urządzenia żądającemu procesowi i blokowanie dostępu innym procesom do czasu zwalniania. Takie rozwiązanie stwarza jednak problem uzależnienie zajętości urządzenia od „kaprysu” procesu. Jeśli proces przekaże tylko część strumienia, a drukowanie reszty będzie musiał odłożyć w czasie, drukarka pozostanie cały czas zajęta. W przypadku spoolingu drukowanie nie rozpocznie się, dopóki cały strumień nie zostanie zbuforowany, dzięki czemu przedłużające się przekazywanie danych nie blokuje innych procesów w dostępie do drukarki.
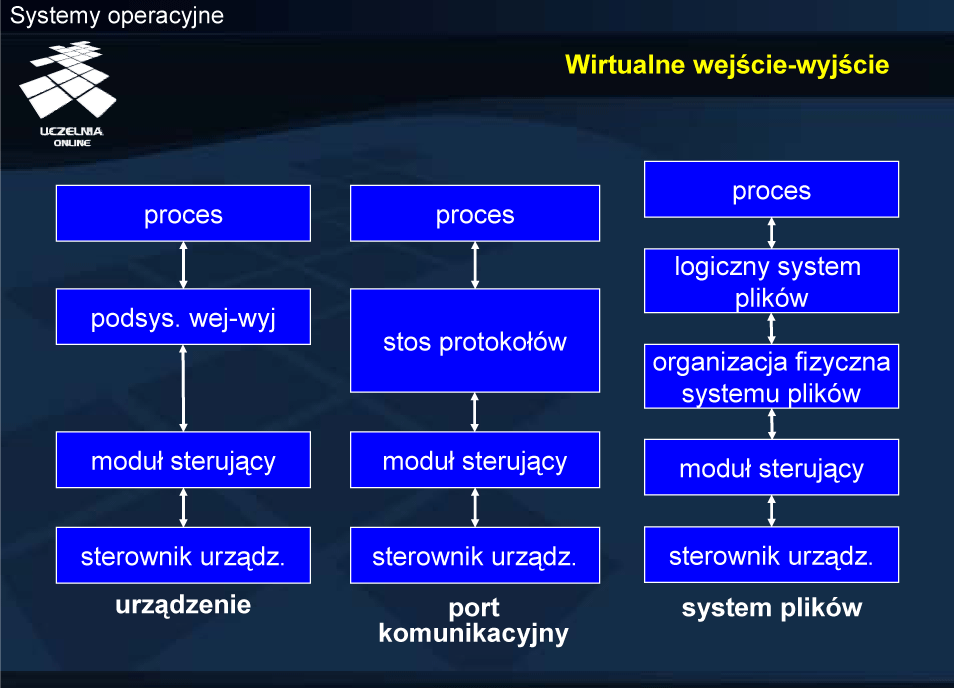
Zarządzanie taką informacją na poziomie aplikacji naraża system na sporo błędów. Dwa różne procesy mogłyby na przykład przydzielić sobie ten sam blok dyskowy. Poza tym zadaniem jądra systemu operacyjnego jest stworzenie środowiska wygodnego dla użytkowników, ułatwiającego wykonywanie programów. Tego typu usługi są wiec realizowane przez oprogramowanie systemowe, które na bazie modułu sterującego urządzenia fizycznego tworzy pewne urządzenia wirtualne, oferujące często zupełnie inny model wykorzystania zasobów urządzeń zewnętrznych.
Dwoma nadmienionymi już przykładami są: protokoły komunikacji sieciowej i system plików. Stos protokołów udostępnia usługi transmisji danych na bazie fizycznej karty sieciowej. Dla aplikacji urządzeniem jest połączenie sieciowe a nie karta. System plików udostępnia logiczny obraz informacji w postaci hierarchicznej struktury katalogów oraz plików identyfikowanych przez nazwy, a moduł organizacji fizycznej systemu plików odwzorowuje ten obraz na zbiór sektorów fizycznego dysku. Dla aplikacji urządzeniem jest więc plik o określonej nazwie, a nie dysk.