Proces służy do organizowania wykonywania programu w ten sposób, że stanowi on powiązanie niezbędnych zasobów systemu komputerowego i umożliwia kontrolę stanu tych zasobów, związaną z wykonywaniem programu.
Istotne jest rozróżnienie pomiędzy procesem a programem. Program jest zbiorem instrukcji. W tym sensie jest tylko elementem procesu, znajdującym się w jego segmencie kodu (zwanym też segmentem tekstu). Poza tym do wykonania programu potrzebne są dodatkowe zasoby (procesor, pamięć itp.) Program najczęściej nie zmienia się w czasie wykonywania (nie ulega modyfikacji), podczas gdy stan procesu ulega zmianie: zmienia się stan wykonywania programu podobnie jak stan większości zasobów z tym związanych. Zmianie w wyniku wykonywania procesu ulega np. segment danych, segment stosu, stan rejestrów procesora itp. Procesem jest więc cały ten kontekst niezbędny do wykonania programu.
Wyodrębnienie procesu wiąże się z współbieżnością przetwarzania. W systemie może istnieć wiele procesów (wiele niezależnych przetwarzań), stąd ważne jest utrzymanie informacji o tym, które zasoby przedzielone na potrzeby każdego przetwarzania. W systemach jednozadaniowych (np. MS DOS) pojęcie procesu nie było wyodrębnione, gdyż nie było takiej potrzeby.

Zasobem jest każdy element systemu, który może okazać się niezbędny dla realizacji przetwarzania. Typowe zasoby kojarzone są z elementami sprzętowymi systemu komputerowego. Należy jednak podkreślić, że to dopiero system operacyjny definiuje taki element jako zasób, gdyż w jądrze systemu istnieją struktury do zarządzania i procedury realizacji przydziału, odzyskiwania itd.
Poza tym część zasobów tworzona jest przez jądro systemu operacyjnego. Zasoby takie często określa się jako wirtualne . Przykładem wirtualnego urządzenia wejścia-wyjścia jest plik. Pliki udostępnia system operacyjny. Na poziomie maszynowym pojęcie takie nie istnieje — można co najwyżej mówić o sektorach dysku, w których składowana są dane.

Operacje przydziału i zwalniania jednostek zasobów dotyczą tworzenia powiązań między procesami i zasobami.
Elementarne operacje wejścia-wyjścia dotyczą również zasobów, ale nie są związane z ich przydziałem, czy zwalnianiem. Są to operacje dostępu do przydzielonych zasobów. Nie wszystkie operacje dostępu do przydzielonych zasobów wymagają jednak wsparcia ze strony jądra. Operacje dostępu do pamięci na przykład realizowane są na poziomie maszynowym, jądro natomiast angażowane jest dopiero w przypadku wykrycia jakichś nieprawidłowości.
Procedury obsługi przerwań z kolei są reakcją na zdarzenia zewnętrzne lub pewne szczególne stany wewnętrzne, mogą być zatem skutkiem ubocznym realizacji dostępu do zasobów. Reakcja na przerwanie może prowadzić do zmiany stanu procesu lub zasobu, nie zawsze jednak taka zmiana jest bezpośrednio spowodowana wykonaniem procedury obsługi. Procedury obsługi przerwań wykonywane muszą być szybko, dlatego ich bezpośrednim skutkiem jest czasami tylko odnotowanie faktu zajścia zdarzenia, natomiast właściwa reakcja systemu, w konsekwencji której nastąpi zmiana stanu procesu lub zasobu, wykonywana jest później.


Strukturę danych na potrzeby opisu stanu procesu określa się jako deskryptor procesu lub blok kontrolny procesu . Zbiór takich informacji dla wszystkich procesów określa się jako tablicę procesów. Współcześnie na potrzeby deskryptorów rzadko wykorzystywana jest rzeczywiście statyczna tablica. Podejście takie gwarantuje szybki dostęp do informacji, ale jest mało elastyczne, gdyż narzuca górny limit na liczbę procesów w systemie, a w przypadku mniejszej ich liczby oznacza marnotrawstwo pamięci.
Zasoby mogą być bardzo zróżnicowane, dlatego ogólny określenie deskryptor zasobu ma raczej charakter pojęciowy, a nie definicyjny. W zależności od rodzaju zasobu struktura opisu może być bardzo różna. Często jest ona narzucona przez rozwiązanie przyjęte na poziomie architektury procesora (np. w przypadku pamięci), a czasami wynika z decyzji projektowych.

Część tych informacji jest jednak niezbędna w każdym deskryptorze. Stan procesu potrzebny jest do podjęcia decyzji odnośnie dalszego losu procesu (np. usunięcie procesu i zwolnienie zasobów, przesunięcie procesu z pamięci fizycznej do pamięci pomocniczej lub odwrotnie itp.). Licznik rozkazów i stan rejestrów niezbędne są do odtworzenia kontekstu danego procesu. Informacje na potrzeby planowania przydziału procesora umożliwiają właściwe szeregowanie procesów i podejmowanie decyzji przez planistów (ang. scheduler), chociaż część tych informacji może znajdować się poza właściwym deskryptorem. Informacje o zarządzaniu pamięcią umożliwiają ochronę obszarów pamięci, w szczególności powstrzymanie procesu przed ingerencją w obszary poza jego przestrzenią adresową. Informacje o stanie wejścia-wyjścia , obejmujące dane o przydzielonych urządzeniach, wykaz otwartych plików itp., umożliwiają odpowiednie zarządzanie tymi zasobami i dostępem do nich przez system operacyjny, ich odzyskiwanie po zakończeniu procesu itp.

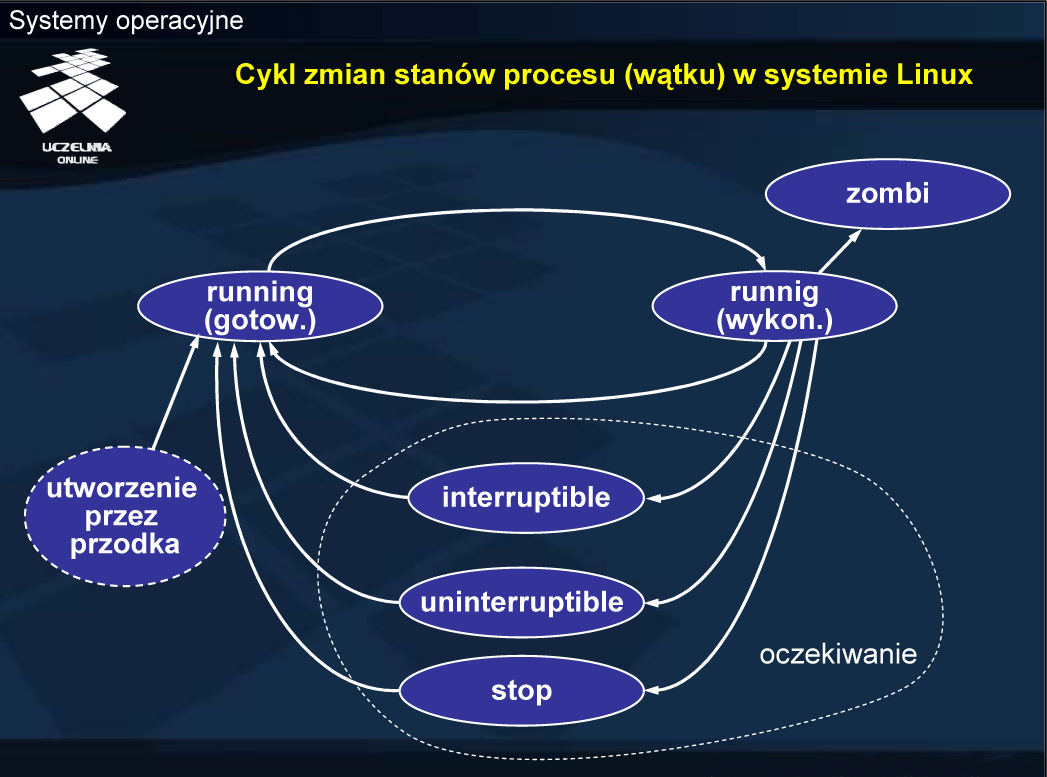
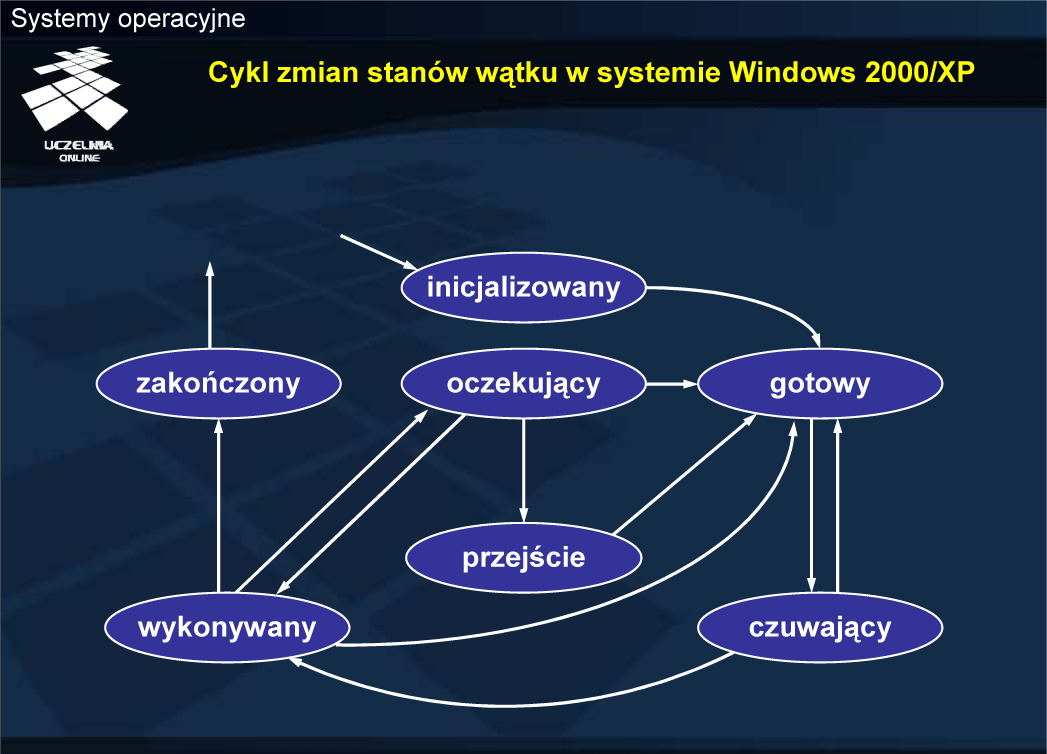
Nowy — formowanie procesu, czyli gromadzenie zasobów niezbędnych do rozpoczęcia wykonywania procesu, z wyjątkiem procesora (kwantu czasu procesora), a po zakończeniu formowania oczekiwanie na przyjęcie do kolejki procesów gotowych.
Wykonywany — wykonywanie instrukcji programu danego procesu i wynikająca z ich wykonywania zmiana stanu odpowiednich zasobów systemu.
Oczekujący — zatrzymanie wykonywania instrukcji programu danego procesu ze względy na potrzebę przydziału dodatkowych zasobów, konieczność otrzymania danych lub osiągnięcia odpowiedniego stanu przez otoczenie procesu (np. urządzenia zewnętrzne lub inne procesy).
Gotowy — oczekiwanie na przydział kwantu czasu procesora (dostępność wszystkich niezbędnych zasobów z wyjątkiem procesora).
Zakończony — zakończenie wykonywania programu, zwolnienie większości zasobów i oczekiwanie na możliwość przekazania informacji o zakończeniu innym procesom lub jądru systemu operacyjnego.
Pozostawanie procesu z stanie zakończony (w systemach uniksopodobnych zwany zombi ) spowodowane jest przetrzymywaniem pewnych informacji o procesie po jego zakończeniu (np. statusu zakończenie). Całkowite usunięcie procesu mogłoby oznaczać zwolnienie pamięci i utratę tych informacji.
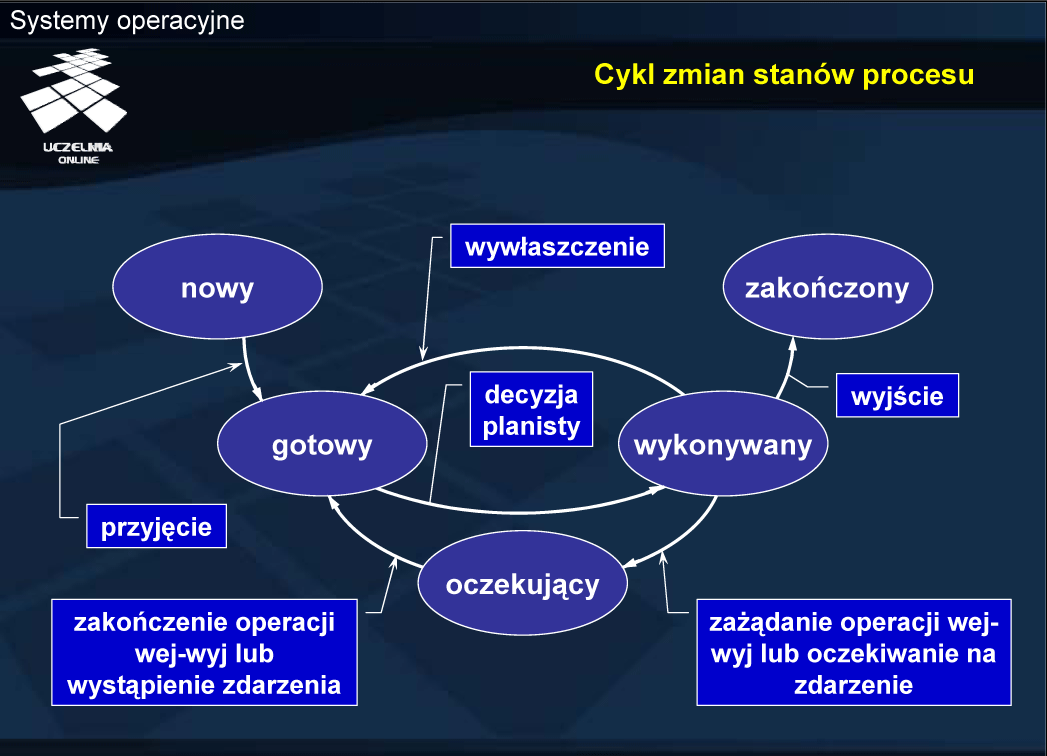
Przejście ze stanu wykonywany bezpośrednio do stanu gotowy oznacza wywłaszczenie procesu z procesora. Wywłaszczenie może być następstwem:
W systemie z podziałem czasu proces otrzymuje tylko kwant czasu na wykonanie kolejnych instrukcji. Upływ kwantu czasu odmierzany jest przez przerwanie zegarowe, a po stwierdzeniu wyczerpania kwantu czasu następuje przełączenie kontekstu i kolejny kwant czasu otrzymuje inny proces (rotacyjny algorytm planowania przydziału procesora).
W systemie z dynamicznymi priorytetami przerwanie zegarowe lub inne zdarzenie obsługiwane przez jądro wyznacza momenty czasu, w którym przeliczane są priorytety procesów. Jeśli stosowane jest wywłaszczeniowe podejście do planowania przydziału procesora, oparte na priorytecie, proces o najwyższym priorytecie otrzymuje procesor. Więcej szczegółów zostanie omówionych w następnym module.

Istotne są też powiązania pomiędzy jednostkami zasobu, a procesami, którym są przydzielone lub które na przydział oczekują. W prezentowanym modelu założono, że informacje o przydzielonych zasobach umieszczone są w deskryptorze procesu, a informacje o oczekiwaniu na przydział umieszczone są w deskryptorze zasobu, ale założenie takie ma raczej charakter poglądowy, niż implementacyjny. W rzeczywistości informacje o powiązaniach mogą być jednocześnie w obu strukturach, jeśli jest to wymagane na potrzeby zarządzania.
Innym zagadnieniem jest implementacja kolejki procesów. Procesy można powiązać w kolejkę wykorzystując odpowiednie wskaźniki w deskryptorze procesu. W deskryptorze procesu oczekującego można więc przechować wskaźnik lub identyfikator następnego (również poprzedniego) procesu w kolejce. Atrybut lista procesów w deskryptorze zasobu może się zatem sprowadzić do czoła takiej kolejki, czyli wskaźnika na deskryptor pierwszego proces, a deskryptor ten będzie zawierał wskaźnik na deskryptor następnego procesu.

Jednostki pewnych zasobów można odzyskać po zakończonych procesach, np. pamięć. Są jednak zasoby, które proces zużywa w ramach przetwarzania, np. energia, istotna w urządzeniach przenośnych, lub czas procesora przed linią krytyczną (nie sam procesor, czy czas procesora ogólnie), istotny w systemach czasu rzeczywistego. Jednostki zasobów, podanych w przykładzie nie są wytwarzane przez procesy w systemie. Zasobem nieodzyskiwalnym wytwarzanym w wyniku przetwarzania mogą być dane lub sygnały synchronizujące.
Jeśli zasób można odzyskać, istotny z punktu widzenia pewnych problemów (np. zakleszczenia) może być sposób odzyskiwania. Zasób wywłaszczalny można odebrać procesowi (np. procesor). Natomiast jednostki zasobu niewywłaszczalnego proces sam musi zwrócić do systemu. Z punktu widzenia systemu oznacza to, że należy poczekać, aż proces, posiadający zasób, dojdzie do takiego stanu przetwarzania, w którym zasób nie będzie mu już potrzebny (np. po wydrukowaniu proces zwróci drukarkę, ale nie papier ani toner).
Pewne zasoby mogą być używane współbieżnie przez wiele procesów, np. segment kodu programu może być czytany i wykonywany przez wiele procesów w tym samym czasie. Są też zasoby dostępne w trybie wyłącznym, czyli dostępne co najwyżej dla jednego procesu w danej chwili czasu (np. drukarka, deskryptor procesu w tablicy procesów).

Kolejkowanie procesów polega na umieszczeniu ich na określonej liście. Jak już wspomniano, do budowy list procesów wykorzystywane są specjalne pola w tablicy procesów, w których dla każdego procesu na liście pamiętany jest identyfikator następnego procesu i/lub poprzedniego procesu.
W tym kontekście, określenie kolejka zadań może się okazać niezręczne — jest to raczej zbiór zadań lub tablica zadań.
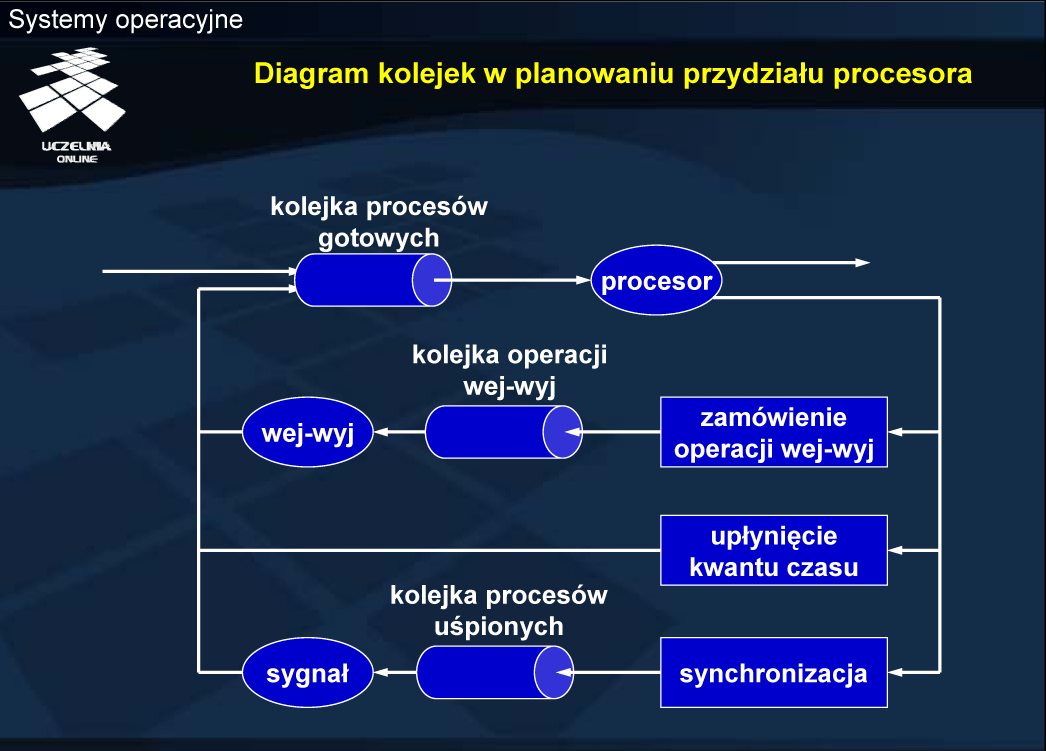
Jeśli proces opuszcza procesor z innych przyczyn, niż upłynięcie kwantu czasu, przechodzi do stanu oczekujący , co wiąże się z umieszczeniem go w kolejce procesów oczekujących na zajście określonego zdarzenia. Kolejek takich może być wiele, np. kolejka może być związana z każdym urządzeniem zewnętrznym, z mechanizmami synchronizacji itp.
Przełączanie kontekstu
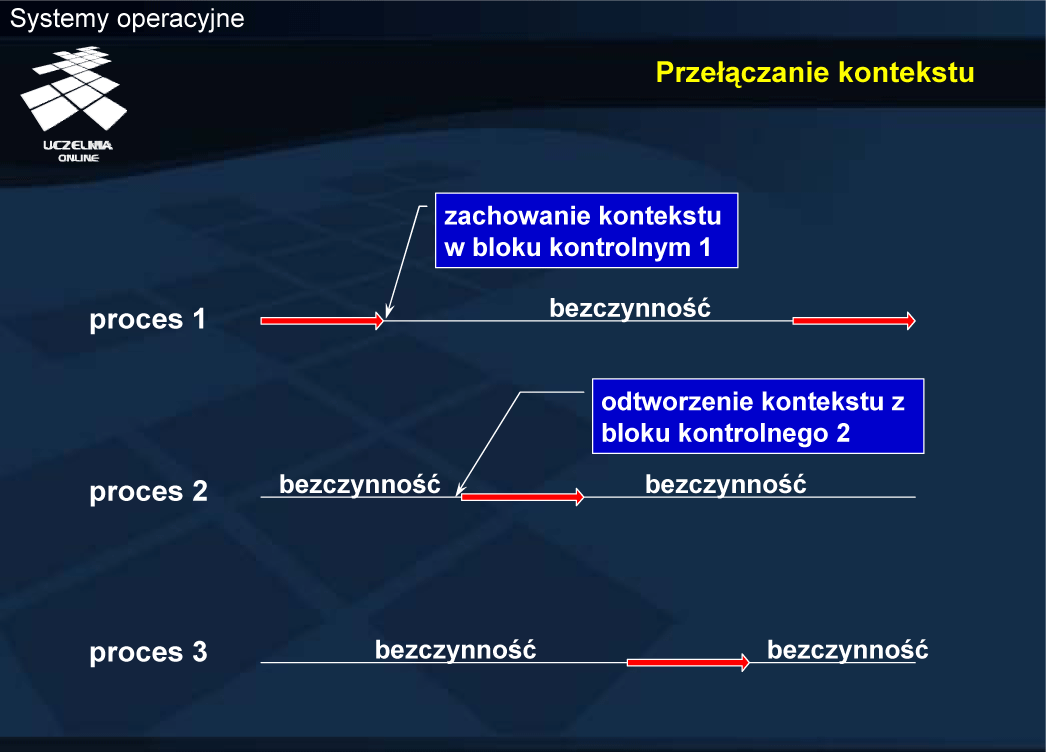
Tak rozumiany kontekst zajmuje niewiele miejsca w pamięci i przechowywany jest w deskryptorze procesu. Przełączanie kontekstu sprowadza się zatem do zaktualizowania we właściwym deskryptorze informacji o kontekście procesu wywłaszczanego z procesora, a następnie załadowaniu rejestrów procesora odpowiednimi wartościami z deskryptora procesu, który ma być wykonywany jako następny.
Czas przełączania kontekstu jest marnowany z punktu widzenie wykorzystania procesora, gdyż żaden program użytkowy nie jest w tym czasie wykonywany. W celu skrócenia czasu przełączania, procesory oferują często wsparcie dla tej operacji w postaci odpowiednich instrukcji lub bardziej złożonych mechanizmów na poziomie architektury.

Ogólnym zadaniem planistów (programów szeregujących) jest wybieranie procesów z pewnego zbioru tak, aby dążyć do optymalizacji przetwarzania w systemie. Kryteria optymalizacji mogą być jednak bardzo zróżnicowane.
W kontekście optymalizacji wykorzystania zasobów mówi się o równoważeniu obciążenia systemu, czyli ogólnie procesora i urządzeń zewnętrznych. Zrównoważenie takie umożliwia osiągnięcie odpowiedniego poziomu wykorzystania zasobów systemu. W przeciwnym razie w systemie może powstać wąskie gardło, którym będzie procesor lub urządzenie zewnętrzne. O procesach, które wykorzystują głównie procesor (np. związane są z realizacją dużej liczby obliczeń) mówi się, że są ograniczone procesorem . Procesy, które większość czasu w systemie spędzają w oczekiwaniu na realizację operacji wejścia-wyjścia, określane są jako ograniczone wejściem-wyjściem (np. edytor tekstu). Wybór procesów tylko z jednej z tych grup może spowodować powstanie wąskiego gardła na intensywnie wykorzystywanym zasobie i tym samym zmniejszyć wykorzystania pozostałych zasobów. W systemach interaktywnych istotny jest tzw. czas odpowiedzi . Zbyt długi czas odpowiedzi grozi zniecierpliwieniem użytkowników i ich irracjonalnym zachowaniem.
W różnego typu systemach rola poszczególnych planistów może być większa lub mniejsza. W systemach interaktywnych zmniejsza się (lub zupełnie znika) rola planisty długoterminowego, a rośnie rola planisty krótkoterminowego. W systemach wsadowych jest dokładnie odwrotnie.
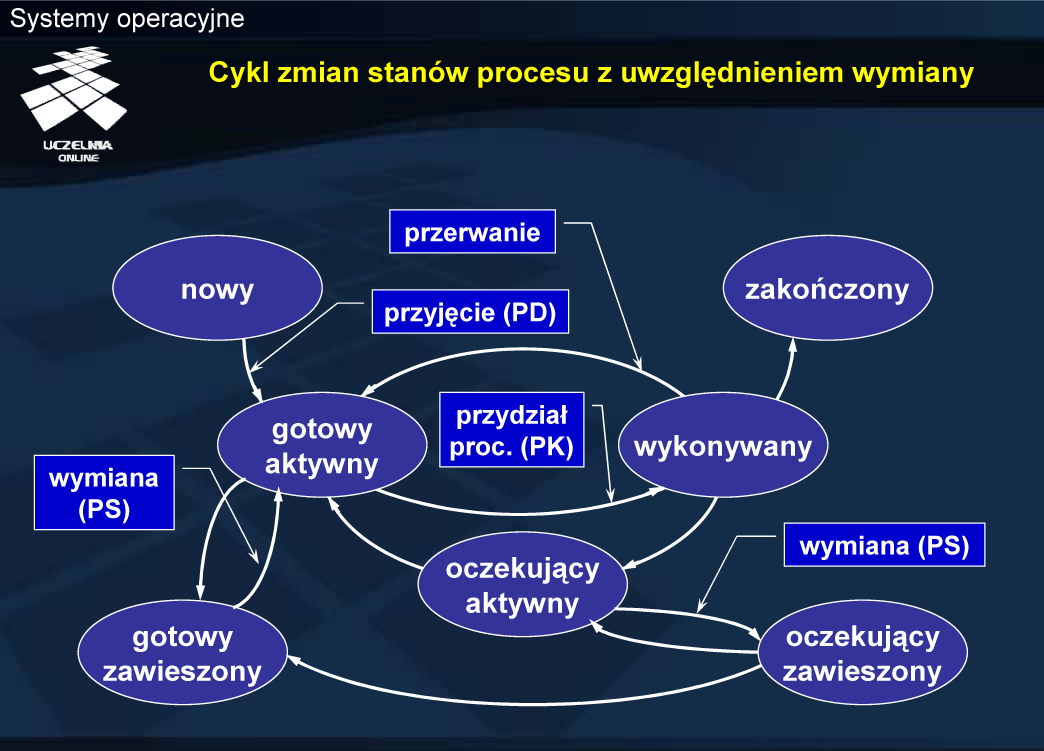
W grafie zmian stanów procesu, oprócz stanów wynikających z wymiany uwzględniono role planistów. Decyzję o przyjęciu nowego procesu do systemu podejmuje planista długoterminowy (PD). Przejście ze stanu gotowy do wykonywany wynika z decyzji planisty krótkoterminowego (PK). Planista średnioterminowy (PS) odpowiada natomiast za wymianę, czyli decyduje o tym, które procesu usunąć z pamięci, a które ponownie załadować. Uwzględniając wymianę, można powiedzieć, że pamięć jest zasobem wywłaszczalnym. W przypadku braku wymiany, odebranie procesowi pamięci oznaczałoby jego usunięcie — pamięć byłaby więc zasobem niewywłaszczalnym.

Elementarne operacje na procesach obejmują: tworzenie, usuwanie, zmianę stanu, zmianę priorytetu. Nie wszystkie operacje na procesach są dostępne dla aplikacji.
Dostępne są operacje tworzenia i usuwania. Proces jest tworzony przez inny proces, w wyniku czego tworzą się zależności przodek-potomek pomiędzy procesami. W systemach uniksopodobnych, zgodnie ze standardem POSIX, do tworzenia służy funkcja fork, która w Linuksie implementowana jest za pomocą bardziej ogólnej funkcji clone. W systemach Windows 2000/XP wykorzystywana do tego celu jest jedna z funkcji: CreateProcess, CreateProcessAsUser, CreateProcessWithLogonW lub (w najnowszych wersjach) CreateProcessWithTokenW.
Usunięcie procesu jest skutkiem zakończenia wykonywania programu, albo wynika z interwencji zewnętrznej. W systemach zgodnych z POSIX proces informuje system o swoim zakończeniu, wywołując funkcję exit lub abort. Do usuwania procesu przez inny proces, albo przez jądro systemu operacyjnego wykorzystywana jest funkcja kill. W systemach Windows 2000/XP dostępne są 2 funkcje: ExitProcess, TerminateProcess.

Nie zawsze też możliwa jest swobodna zmiana priorytetu. Funkcja nice w systemach standardu POSIX zmienia np. tylko pewną składową priorytetu procesu, podczas gdy właściwa wartość priorytetu zależy od kilku innych czynników. Zostanie to omówiony przy okazji szeregowania procesów.


W programie dobrze jest zatem wówczas wyodrębnić takie niezależne fragmenty i wskazać systemowi, że można je wykonać w dowolnej kolejności lub nawet współbieżnie, w miarę dostępnych zasobów. Taki wyodrębniony fragment określa się jako wątek . Wątek korzysta głównie z zasobów przydzielonych procesowi — współdzieli je z innymi wątkami tego procesu. Zasobem, o który wątek rywalizuje z innymi wątkami, jest procesor, co wynika z faktu, że jest on odpowiedzialny za wykonanie fragmentu programu. Wątek ma więc własne sterowanie, w związku z czym kontekst każdego wątku obejmuje licznik rozkazów, stan rejestrów procesora oraz stos. Każdy wątek musi mieć swój własny stos, gdzie odkładane są adresy powrotów z podprogramów oraz alokowane lokalne zmienne.

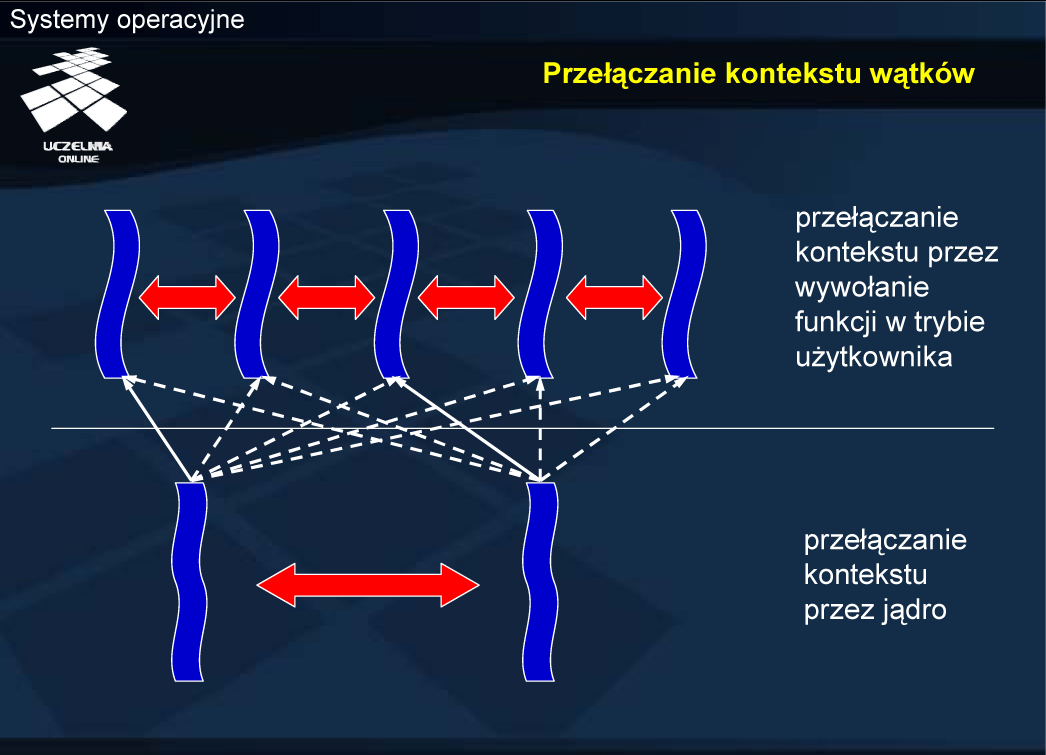
Alternatywą jest zarządzanie wątkami w trybie systemowym przez jądro, które utrzymuje deskryptory i odpowiada za przełączanie kontekstu pomiędzy wątkami.
Istotne w obsłudze wielowątkowości, niezależnie od sposobu realizacji, jest dostarczenie odpowiednich mechanizmów synchronizacji wątków wewnątrz procesu. Potrzeba synchronizacji wynika z faktu współdzielenia większości zasobów procesu. Problemy synchronizacji będą przedmiotem rozważań w innym module.

Z drugiej strony, świadomość istnienia wątków procesu umożliwia uwzględnienie tego faktu w zarządzaniu zasobami przez jądro i prowadzi do poprawy ich wykorzystania.

Realizacja wątków przez odpowiednią bibliotekę w trybie użytkownika zwiększa szybkość przełączania kontekstu, ale powoduje, że jądro, nie wiedząc nic o wątkach, planuje przydział czasu procesora dla procesów. Oznacza to, że w przypadku większej liczby wątków procesu czas procesora, przypadający na jeden wątek jest mniejszy, niż w przypadku procesu z mniejszą liczbą wątków.
Problemem jest też wprowadzanie procesu w stan oczekiwania, gdy jeden z wątków zażąda operacji wejścia-wyjścia lub utknie na jakimś mechanizmie synchronizacji z innymi procesami. Planista traktuje taki proces jako oczekujący do czasu zakończenia operacji, podczas gdy inne wątki, o których jądro nie wie, mogłyby się wykonywać.
W niektórych systemach operacyjnych wyróżnia się zarówno wątki trybu użytkownika, jak i wątki trybu jądra. W systemie Solaris terminem wątek określa się wątek, istniejący w trybie użytkownika, a wątek trybu jądra określa się jako lekki proces . W systemie Windows wprowadza się pojecie włókna , zwanego też lekkim wątkiem (ang. fiber, lightweight thread), które odpowiada wątkowi trybu użytkownika, podczas gdy termin wątek odnosi się do wątku trybu jądra. Takie rozróżnienie umożliwia operowanie pewną liczbą wątków trybu jądra, a w ramach realizowanych przez te wątki programów może następować przełączanie pomiędzy różnymi wątkami trybu użytkownika bez wiedzy jądra systemu. Wątek trybu jądra można więc traktować jako wirtualny procesor dla wątku trybu użytkownika.



Tworząc nowy proces z użyciem funkcji clone można określić, które zasoby procesu macierzystego mają być współdzielone z potomkiem. W zależności od zakresu współdzielonych zasobów, nowo utworzony proces może być uznawany za wątek lub za ciężki proces. Typowe wątki będą współdzielić przestrzeń adresową, otwarte pliki i inne informacje związane z systemem plików (np. katalog bieżący, korzeń drzewa katalogów) i procedury obsługi sygnałów.
Rozróżnienie proces ciężki – proces lekki sprowadza się zatem do określenia zakresu współdzielenia zasobów.